Keyword [Global Average Pooling]
Zhou B, Khosla A, Lapedriza A, et al. Learning deep features for discriminative localization[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2921-2929.
1. Overview
1.1. Motivation
- recent work find that various layers of CNN behave as object detectors despite on supervision on the location of the object was provided. This ability is lost when FC are used for classification
In this paper
- revisit global average pooling layers, shed light on how it explicitly enables CNN to have remarkble localization ability despite being trained on image-level labels

1.2. Related Work
- Weakly-supervised Object Localization
- global max pooling
- Visualizing CNNs
- DeConv
1.3. Class Activation Mapping (CAM)
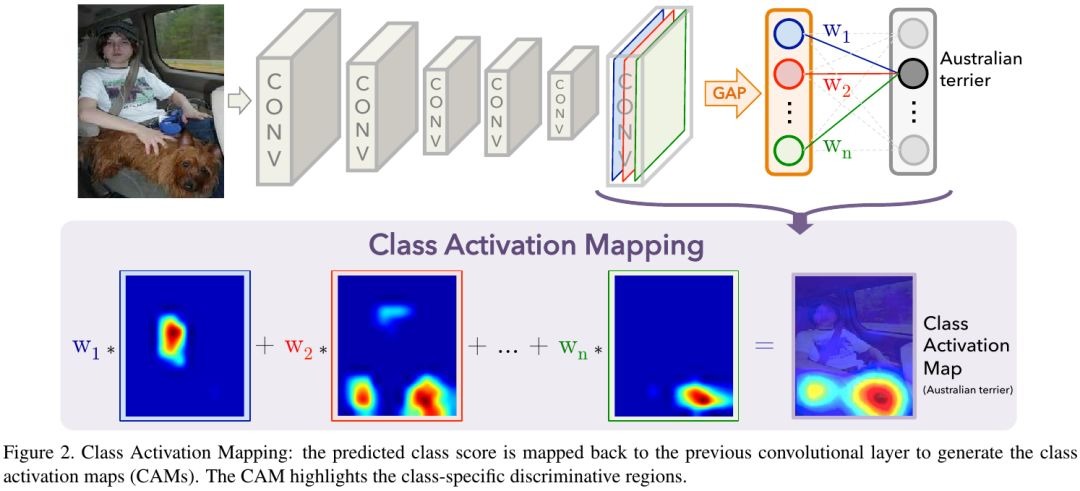
- before final ouput layer, perform global average pooling on CNN feature
- then FC layer to produce the desired output
- finally, project back the weights of the output layer on CNN features
1.3.1. Formulation
For feature maps (K, h, w)
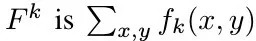
- f_k (1, h, w). feature map of kth channel
- F^k (1, 1, 1). kth channel feature after GAP

- final FC layer (K, C)
- w^c (K, 1)
- S_c (C)
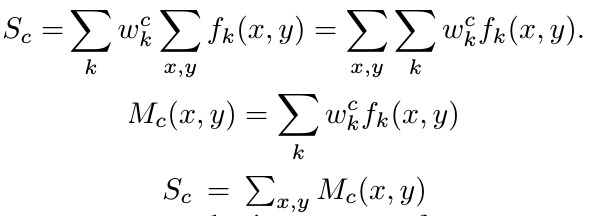
- simply upsample the class activation map to the size of the input image
1.3.2. GAP vs GMP
- GMP. encourages to identify one discriminative part
- GMP. low scores for all image regions except the most discriminative one do not impact the score
2. Experiments
2.1. Weakly-supervised Object Localization
- find that the localization ability of the networks improved when the last Conv before GAP had a higher spatial resolution (13x13 for AlexNet, 14x14 for VGG, 14x14 for GooLeNet)
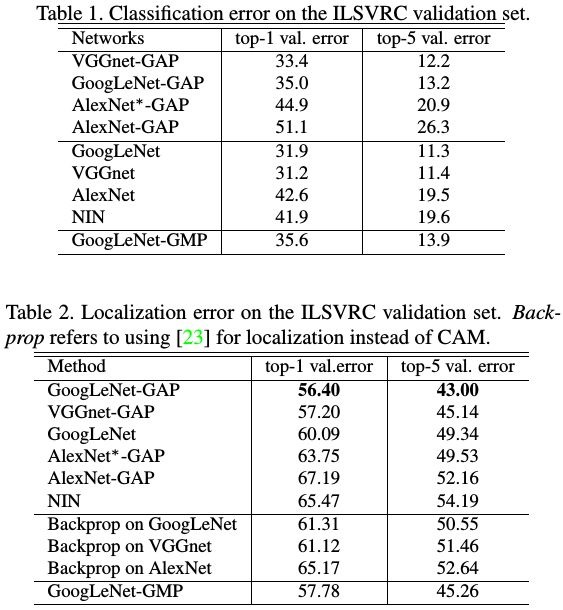
2.1.1. Localization
- value above 20% of the max value of CAM
- take the BBox covers the largest connected component in the segmentation map (top-5 predicted classes)

2.2. Visualize Class-Specific Units
